Exploring Carbohydrates
Historically, small molecules such as glucose, fructose, and sucrose have been collectively called "sugars." Chemical research has shown that these molecules are composed of carbon, oxygen, and hydrogen with the typical formula of (CH2O)n. Sugars are part of a family of chemicals called "carbohydrates." Although the terms "sugar" and "carbohydrate" are often used interchangeably in many discussions, glycobiologists who study the structure, biosynthesis, and functions of carbohydrates prefer to use more specific terms such as saccharides (for sugars) and glycans for their polymers.
Glycans have specific 3D shapes and functions in biology. While proteins are made of building blocks called amino acids, glycans are composed of sugar units or "monosaccharides" (such as glucose and fructose), linked together through specific bonds to form "oligosaccharides" (such as sucrose and lactose, comprised of a few monosaccharides) and "polysaccharides" (such as starch and cellulose, comprised of many monosaccharides). Unlike protein, where amino acids are linearly linked via standard peptide bonds, the bonds linking monosaccharides can be at different locations, allowing glycans to form branched chains with unique shapes and functions. Although glycans are an important class of biological macromolecules, they can link to other macromolecules such as proteins and lipids to enhance their properties and functions. This is why learning about the compositions and shapes of glycans can help us understand the functions of these molecules.
Common monosaccharides contain either five carbons (pentoses like ribose) or six carbon atoms (hexoses like glucose). These carbon atoms are linked to each other in a chain and have hydrogen atoms, hydroxyls, ketones, or aldehyde groups attached to them. Most biological monosaccharides form closed ring structures. The carbonyl carbon reacts with a hydroxyl group in the same molecule, four or five carbons away. The resulting hemiacetal or hemiketal connects the carbonyl carbon (called the anomeric carbon) to another carbon atom via an oxygen atom to form a 5- or 6-membered ring. In this ring structure the hydrogen atom and hydroxyl group can be attached to the anomeric carbon in two different ways, forming two stereoisomers called alpha (ɑ) and beta (β) (Figure 1). In order to form oligosaccharides or polysaccharides, the hydroxyl group attached to the anomeric carbon links to a specific carbon in the next saccharide.

|
| Figure 1. Glucose, a monosaccharide, shown in its linear and cyclic forms. The standard numbering of carbon atoms is shown, and the two possible conformations of the cyclic form (alpha and beta) are shown at right. Maltose is a disaccharide composed of two glucose molecules, and cellulose is a polysaccharide composed of thousands of glucose molecules. Notice that the glycosidic bond connecting the monosaccharides in maltose and cellulose are slightly different. |
Specialized carbohydrates may be oxidized or have other chemical groups attached to the hydroxyls for specific functions. For example, the blood carbohydrate heparin has many sulfate groups attached along the chain, small sugars in metabolism are often phosphorylated, and most protein glycosylation includes sugars with amino and acetyl groups. Sugars also may be found as part of more complex molecules such as nucleotides.
For more information on the details of carbohydrate structure, see the textbook "Essentials of Glycobiology."
Importance of Carbohydrates in Biology
Carbohydrates play many essential roles in cells ranging from energy transactions, to structural roles, recognition, and signaling.
Simple sugars drive the energy cycle of the entire ecosystem. Glucose is the primary sugar used for energy. Plants can harvest energy from light to make glucose from water and carbon dioxide (by a process called photosynthesis). Plants and the many organisms that eat them use glucose to build ATP through glycolysis, the tricarboxylic acid cycle and oxidative phosphorylation. Glucose may be stored in larger polysaccharides such as starch and glycogen.
Polysaccharides may be linear or branched, and play many functional roles. The many shapes that are possible in carbohydrate chains allow the construction of materials with diverse properties. Cellulose, the most abundant molecule on the Earth, is a linear chain and 18 strands associate side-by-side to form a tough cable. Pectin, on the other hand, has many branches and forms a disordered random tangle that fills the spaces between cellulose fibers in plant cell walls. Heparin (Figure 2; 3irl) is a sulfated polysaccharide that is used as blood thinner. The connections between the component monosaccharides also make a big difference--for example, the cellulose in wood and starch that we eat are both composed of strings of glucose, but connected in different ways. Human digestive enzymes can break down starch to produce glucose molecules that are absorbed by intestinal cells, but we do not have any enzymes to digest cellulose.
Many extracellular proteins (proteins that are secreted by cells) and membrane proteins with extracellular domains may be glycosylated with short, branched oligosaccharides. The sugars are added in the endoplasmic reticulum of eukaryotic cells, while the proteins are being synthesized. Even viral proteins, such as the coronavirus spike protein (Figure 2; 7kip), produced by infected human cells are glycosylated. The glycans are typically added to the hydroxyl side chain of serine or threonine amino acids ("O-glycosylation") or to the amide group of asparagine ("N-glycosylation"). There are also examples of rare linkages of glycans to cysteine side chains (“S-glycosylation”) in some proteins. Each organism has a distinctive collection of sugars decorating their proteins, which is controlled by the collection of proteins that participate in the glycosylation. In fact each person has a unique glycan signature, leading for example to different blood types: some people have enzymes to make A-type glycans, some have enzymes for B-type glycans, and some have neither, forming O-type glycans. Matching the A, B, and O blood group antigens have important consequences in medicine, especially in blood transfusions and organ transplants.
Some pathogens recognize cell surface glycans when infecting cells. For example, the cholera causing organism produces a toxin that binds to cells at one of two glycans - the GM1 ganglioside and the O-type blood antigen (Figure 2; 5elb).

|
| Figure 2. Examples of carbohydrates in the PDB: the coronavirus spike protein (left; 7kip) with many sites of glycosylation in gray; a fragment of heparin (center; 3irl), shown with a ball-and-stick representation; and cholera toxin bound to a small fragment of O-type blood glycans (right, 5elb), with the glycans shown using SNFG representation. |
Representing Carbohydrates
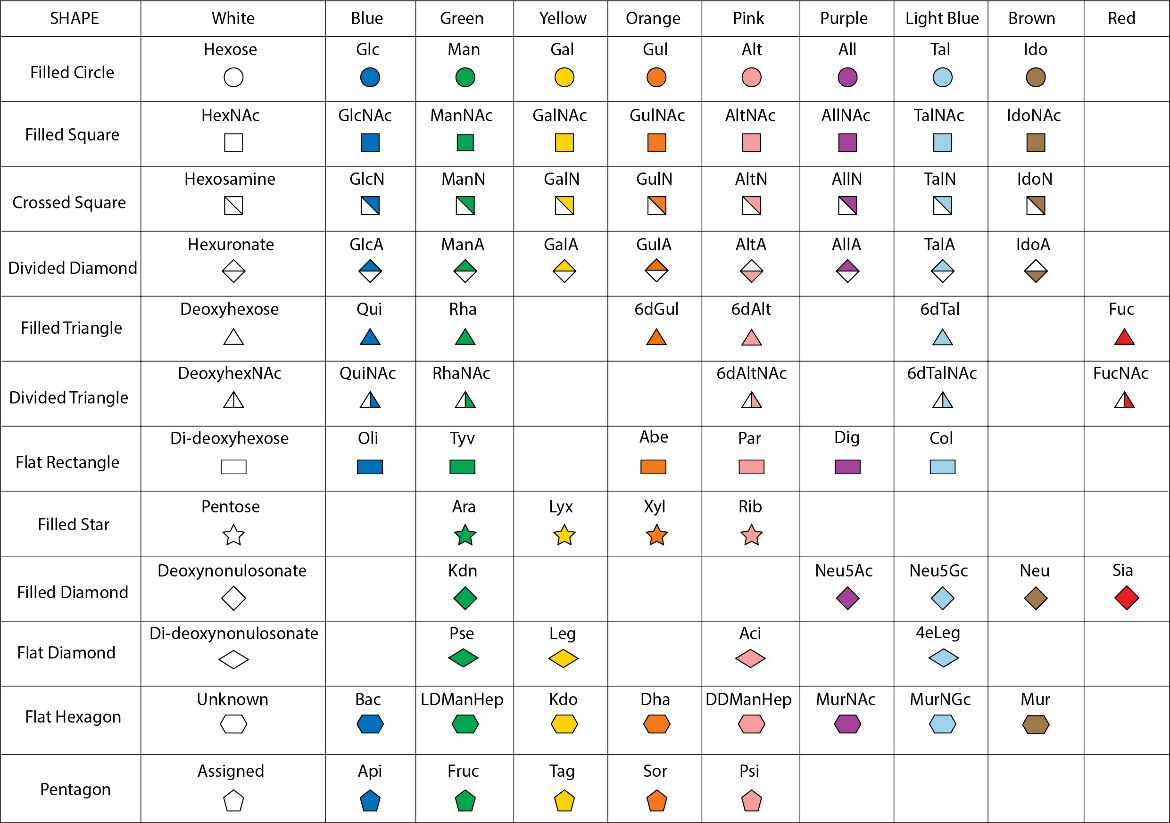
Researchers have developed a standard way of visually representing diverse glycan structures, using the Symbol Nomenclature for Glycans (SNFG) representation (Figures 3 and 4). SNFG representations specify the component sugars and the way they are connected together. Each monosaccharide is represented by a unique symbol (such as the blue circle for glucose). Connections between the saccharides are described by the stereospecificity of the anomeric carbon (ɑ or β) and the atom numbers of the two connecting atoms. For example, In Figure 3, the SNFG representation includes the stereochemistry and atom numbers of each connection, for example, in cellulose, position #1 (no marker by default) in a beta anomer ring is connected to the #4 position in the neighboring ring.

|
| Figure 3. Structures of small fragments of cellulose and starch, with their SNFG representation. The structures shown here were taken from the complex of cellulose with expansion, a protein that loosens cellulose fibers (4fer), and starch bound to the digestive enzyme alpha-amylase (5td4). |
|
| Figure 4. Standard Symbol Nomenclature for Glycans (SNFG) symbol nomenclature. For a detailed description and tools for using these symbols, visit the SNFG site. |
How Carbohydrates are Specified in PDB Entries
In 2020, members of the wwPDB worked together to ensure that carbohydrates in PDB structures are represented in a consistent way, improving methods for finding carbohydrate-related entries. All carbohydrate-containing entries in the PDB archive were remediated. This project incorporated standards used by the glycoscience community to enable easy translation of PDB data to other representations commonly used by glycobiologists.
Detailed information about this remediation is described at wwPDB.org.
In the PDB archive, monosaccharides are treated as ligands, and oligosaccharides are treated as branched entities composed of monosaccharides and assigned unique chain ids. Common oligosaccharides such as sucrose and lactose, are represented as branched entities of connected monosaccharides. Additionally, the entirety of these common oligosaccharides are also represented as "biologically-interesting molecules" (BIRD) to facilitate search and review. For example, this allows users to search for common names like "sucrose."
Please note, it is not uncommon for portions of a biological macromolecule to be unresolved in experimental data. Segments of carbohydrates may be fully or partially missing from the atomic coordinates (i.e., they could not be modeled from available experimental data). In glycosylated proteins, often only the first sugar of the chain is resolved and included in the coordinates for the PDB entry. In these cases (where only a single sugar is resolved), the sugar will be presented as a ligand. Other sites of glycosylation, if they contain two or more resolved sugars, will be treated as separate branched entities.
Finding carbohydrates in the archive
The RCSB PDB website offers different ways to access, analyze, and visualize carbohydrate data. The main search bar at RCSB.org may be used in many cases by entering the name of a component sugar, oligosaccharide, or polysaccharide. For example, try searches on "sucrose", "FRU", "heparin", "cellulose," etc. This will often return a list of entries that include the carbohydrate and also entries related to the carbohydrate. Use the "Unique Ligands" and "Unique branched monosaccharides" fields in the search result list to help you find the most relevant molecules.
You can also use the "Advanced Search" to refine your search.
- For monosaccharides, use the "Chemical Components" category just as you would for any other ligand.
- For oligosaccharides, use the "Oligosaccharide/Branched Molecular Features" category, which includes options for types, components, and common oligosaccharide descriptors.
- For glycosylation, use the “Polymer Molecular Features” category which allows you to search for specific glycosylation types.
A few sample advanced searches:
Show me all entries with glycosylation
Use the advanced search category: "Polymer Molecular Features->Glycosylation site"
Select “exists”
Show me all entries with fructose in an oligosaccharide
Use the advanced search category: "Oligosaccharide/Branched Molecular Features->Oligosaccharide Component List"
Enter "FRU"
What is the largest oligosaccharide in the archive?
Use the advanced search category: "Oligosaccharide/Branched Molecular Features->Oligosaccharide Component Count"
This reports "Enter an integer between 2 and 36"
Enter a value of 36, which will return 3irl, the heparin structure shown in Figure 2
The "Oligosaccharides" Section of the Structure Summary Page
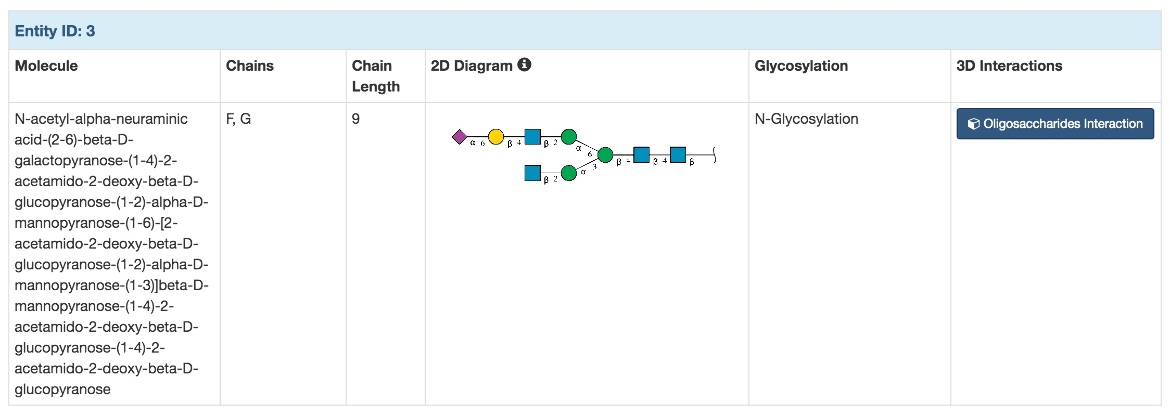
|
| Figure 5. Oligosaccharide section for PDB structure 4q6y. |
Every PDB structure has a corresponding Structure Summary Page at RCSB.org. The "Oligosaccharides" section in the Structure Summary Page includes a brief summary of information about oligosaccharides included in the entry. This includes a full molecular name, the Chain IDs of entities included in the entry, the length and SNFG diagram of the oligosaccharide, a section that specifies if the oligosaccharide is part of glycosylation of a macromolecule, and a link to a Mol* visualization of interactions of the oligosaccharide with macromolecules in the entry (see below). For example, Figure 5 shows N-glycosylation from a glycoengineered antibody domain (4q6y).
Viewing Carbohydrates in Mol*

|
| Figure 6. Mol* representations of glycosylation in the small hormone chorionic gonadotropin (1hd4) |
Mol* has many options for displaying carbohydrates (and proteins). By default, it will display carbohydrates as 3D versions of the SNFG symbols overlayed on a transparent ball-and-stick diagram. By using options in the "Components" menu, you can also display only the ball-and-stick diagram, space filling representations, and many other choices. A small hormone chorionic gonadotropin (1hd4), which includes one site of N-glycosylation, is displayed in Figure 6 in several representations using Mol*.
